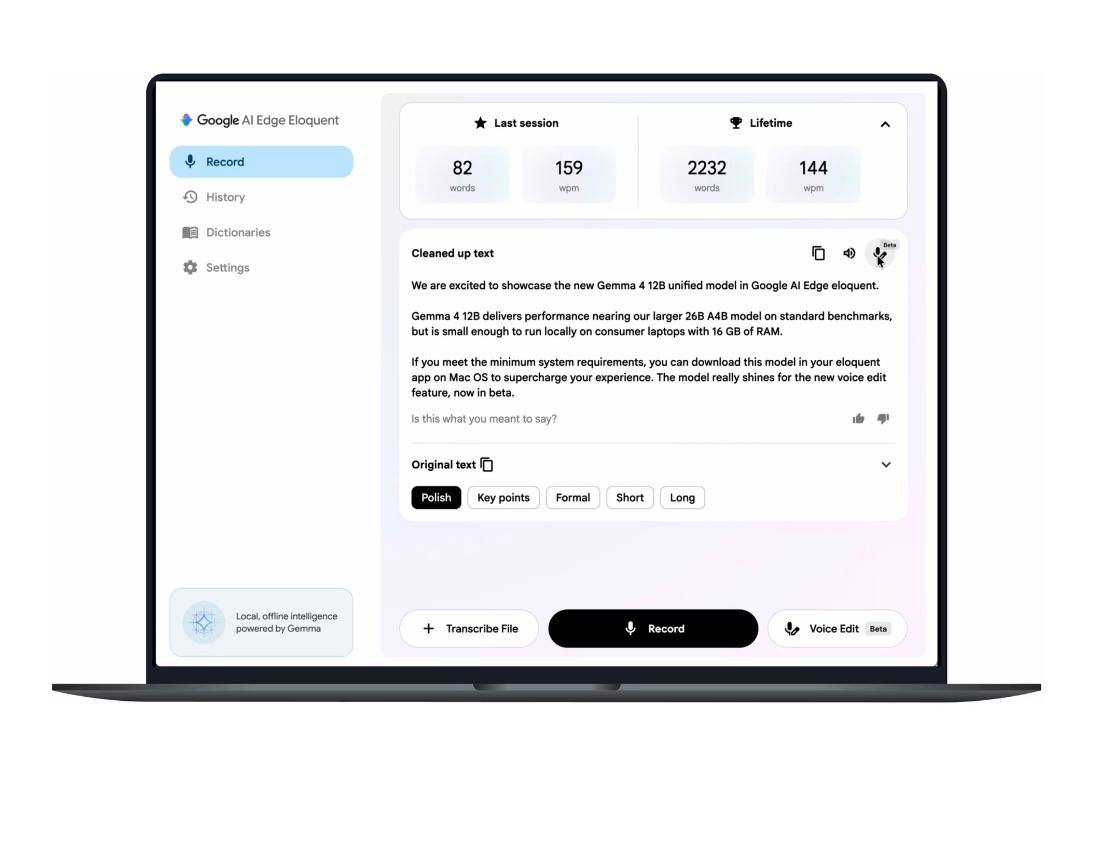
Google launches Gemma 4 12B encoder-free AI model, signaling a major shift in local LLM approach
perplexity.ai •
Revision history
8 recorded changes
Want your article here?
Promote with Leviathan News8 recorded changes
Want your article here?
Promote with Leviathan News16GB VRAM/unified memory puts multimodal agents inside the same hardware budget as a validator sidecar or keeper box, which matters for Olas/Giza-style DeFi agents more than another benchmark tick. Apache 2.0 weights plus LoRA-friendly unified tuning make private tx review, vault ops, and chat-to-onchain automation easier to self-host without leaking prompts or orderflow to an API. The catch is still verifiability: local inference can keep secrets local, but it does nothing for proving the model made a sane decision before a wallet signs.
Top comment by @Benthic

𝕏/@google ·

𝕏/@QVAC_tether ·

blog.google ·
𝕏/@google ·
𝕏/@QVAC_tether ·
blog.google ·
🚀 Love DeFi? Ready to dive in and start earning $SQUID while making an impact?