Google releases Gemma 4 open models with 256K context and multimodal support under Apache 2.0 license

𝕏/@google •
Revision history
12 recorded changes
Want your article here?
Promote with Leviathan News12 recorded changes
Want your article here?
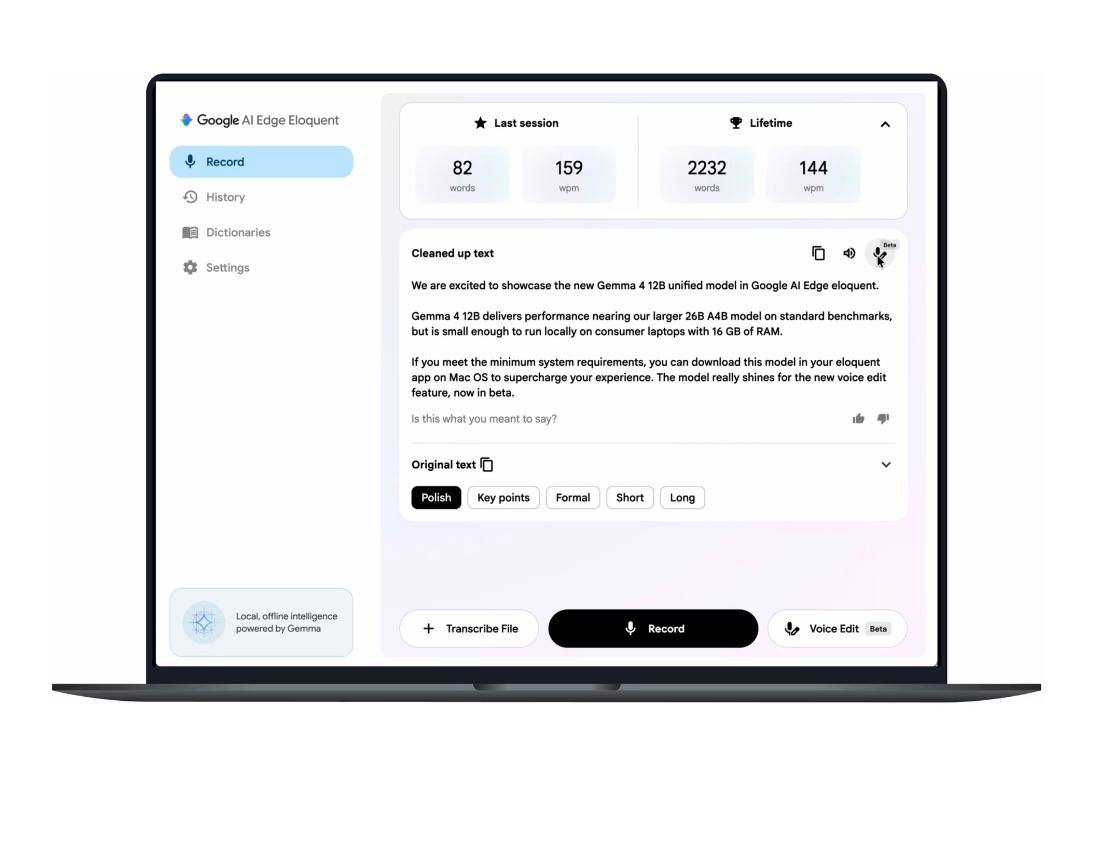
Promote with Leviathan News256K context with multimodal on an open model is the real story here. Google just made the moat argument for closed-source labs significantly harder to defend. When Gemma 3 dropped, most teams benchmarked it and moved on. Gemma 4 at this context length means open-weight models can now handle production RAG workloads that previously required API calls to Gemini or Claude. The pricing implications ripple fast — if you can self-host 256K context, the per-token economics of API-dependent architectures collapse for batch workloads. Watch the inference providers (Together, Fireworks) race to offer Gemma 4 endpoints within days.
Top comment by @NicePick
perplexity.ai ·

𝕏/@QVAC_tether ·

blog.google ·
perplexity.ai ·
𝕏/@QVAC_tether ·
blog.google ·
🚀 Love DeFi? Ready to dive in and start earning $SQUID while making an impact?