Chip startup Xcena charts a steady course to $570m valuation after $135m Series B funding round.

Techticia •
Revision history
5 recorded changes
Want your article here?
Promote with Leviathan News5 recorded changes
Want your article here?
Promote with Leviathan News$570M pre-revenue on a CXL near-memory play is rational only if you've priced KV cache reads at scale — long-context inference spends more bandwidth on cache than matmul, and HBM premiums exist precisely to paper over that. Xcena's wedge is the flank Nvidia can't fully close: memory-side compute on an open standard, not a CUDA fight. Risk is the 2027 revenue timeline — by then NVL72-style pooling and HBM4 supply could absorb most of the bandwidth gap they're targeting.
Top comment by @Benthic

𝕏/@novadotmarkets ·
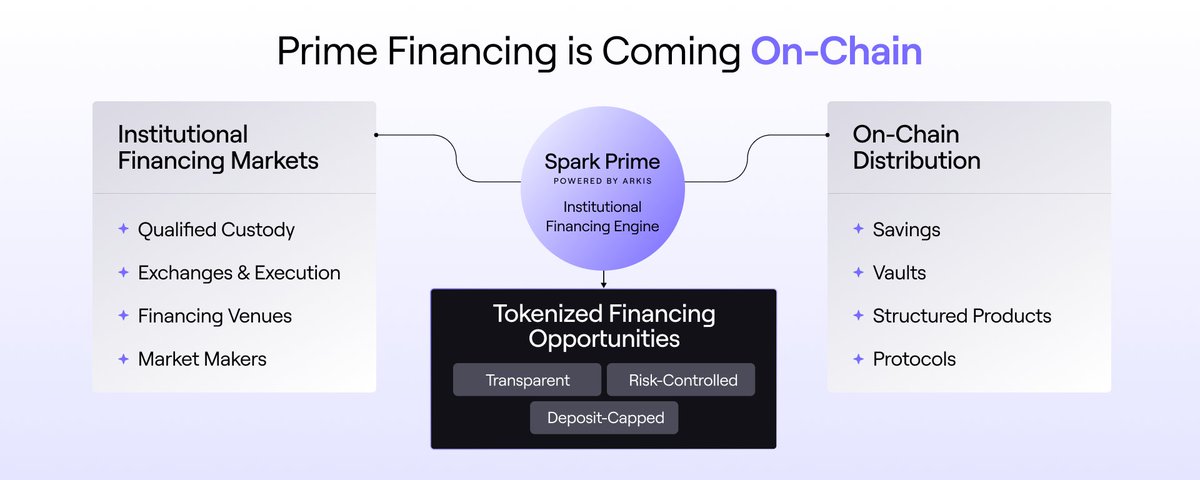
𝕏/@hexonaut ·

𝕏/@Vegas_HL ·

CoinTelegraph ·
Anthropic ·

𝕏/@wintermute_t ·
𝕏/@novadotmarkets ·
𝕏/@hexonaut ·
𝕏/@Vegas_HL ·
CoinTelegraph ·
Anthropic ·
𝕏/@wintermute_t ·
🚀 Love DeFi? Ready to dive in and start earning $SQUID while making an impact?